1. Unicode and UTF-8
Unicode is character set. UTF-8 is a way of decoding for unicode. And it includes UTF-16, UTF-32.we can find the unicode of a character by searching the standard. The UTF-8 decode can be calculated by unicode.
2. str and unicode in python 2
str and unicode are two types.
str stores the bytes after encoding. When outputting, every byte is presented by 16 digits, starting with \x. Every chinese character has three bytes.
str can be converted to unicode by decode() method.
example:
a.decode('utf-8')
unicode can be converted to str by encode() method.
example:
b.encode('utf-8')
ENCODE METHODS
1. head of a script
#-*- coding: utf-8 -*-
or
# coding=utf-8
if we do not set up, the default one is ascii. And you will get error.
2. sys.stdin.encoding and sys.stdout.encoding
3. sys.getdefaultencoding()
CHARACTER SET CONCATENATION
when concatenating str and unicode, the output is unicode. first decode str to unicode by decode(), then concatenating. Sometimes we will have errors.
READ IN FILE AND JSON
read in a file and we get str type, presented as 16-digits starting by "\x".
f=open('t.txt')
a=f.read()
a:
'{"hello":"\xe5\x92\xa9"}\n'
can be decoded to unicode by json
json.loads(a)
{u'hello':u'\u54a9'}
OUTPUT
str can be outputed to files. unicode needs to be encoded to str by encode()
COMPUTE md5
md5 computation requires unicode to be encoded to str first.
hashlib.md5(a).hexdigest()
OUTPUT TO STDOUT
when outputing to stdout , default encoding is sys.stdout.encoding, it depends on the default setting of the system.
import sys
sys.stdout.encoding
'UTF-8'
in the environment of zh_CN.GB2312, default is not UTF-8, we can not output normally.
COMMAND PARAMETER READIN
the parameters gotten by sys.argv and argparse are all str type, presented as 16-digits starting with \x. We can get encoding type by sys.stdin.encoding , and then convert to unicode.
#! /usr/bin/evn python
# coding =utf-8
import sys
print repr(sys.argv[1])
print sys.stdin.encoding
print repr(sys.argv[1].decode(sys.stdin.encoding))
python hello.py "哇嘿嘿”
'\xe5\x93\x87\xe5\x98\xbf\xe5\x98\xbf'
UTF-8
u'\u54c7\u563f\u563f'
CHARACTER START WITH \u CONVERTED TO UNICODE
b='\u54a9'
b
'\\u54a9'
convert b to chinese
1. unicode-escape
unicode(b,'unicode-escape')
u'\u54a9'
or
b.decode('unicode-escape')
u'\u54a9'
2. eval concatenation
eval('u"'+b.replace('"',r'\"')+'"'
u'\u54a9'
Monday, December 4, 2017
Python package structures and how to build a package automatically
A python package usually has the following structure:
funniest/ funniest/ __init__.py command_line.py tests/ __init__.py test_joke.py test_command_line.py MANIFEST.in README.rst setup.py .gitignore
http://python-packaging.readthedocs.io/en/latest/everything.html
To build one package automatically, one can use cookiecutter
https://www.pydanny.com/cookie-project-templates-made-easy.html
https://github.com.audreyr/cookiecutter-pypackage.git
Thursday, October 12, 2017
Some sourcetree, stash tutorial
Atlassian Stash tutorial:
https://www.youtube.com/watch?v=QWS2yXehCNk
Sourcetree tutorial:
https://www.youtube.com/watch?v=PkVMgh1q33Q
More stash:
https://www.youtube.com/watch?v=y9rTRk-5uSQ
https://www.youtube.com/watch?v=QWS2yXehCNk
Sourcetree tutorial:
https://www.youtube.com/watch?v=PkVMgh1q33Q
More stash:
https://www.youtube.com/watch?v=y9rTRk-5uSQ
If your web.py read in some garbage character, try this method
I once used the python web.py to set up a web service. But when reading in non English words, it will show garbage characters.
Here is a way to fix that problem.
add the two lines at the top of the script:
Here is a way to fix that problem.
add the two lines at the top of the script:
#!/usr/bin/env python# -*- coding:utf-8 -*-
Add the lines to the beginning import of the script:
import sys reload(sys) sys.setdefaultencoding('utf-8')Add the header in the get function like below.It will solve the problem.

Tuesday, September 26, 2017
Monday, September 25, 2017
Parse Amazon url to get the reviews
Parse Amazon url to get the reviews:
https://www.scrapehero.com/how-to-scrape-amazon-product-reviews/
web scraping to get the reviews using beautifulsoup:
https://www.dataquest.io/blog/web-scraping-beautifulsoup/
https://www.scrapehero.com/how-to-scrape-amazon-product-reviews/
web scraping to get the reviews using beautifulsoup:
https://www.dataquest.io/blog/web-scraping-beautifulsoup/
Friday, September 22, 2017
Get movie reviews and rating from Amazon API
Get movie reviews and rating from Amazon API

https://media.readthedocs.org/pdf/python-amazon-product-api/0.2.5a1/python-amazon-product-api.pdf
Latest Amazon python api doc
https://media.readthedocs.org/pdf/python-amazon-product-api/latest/python-amazon-product-api.pdf

https://media.readthedocs.org/pdf/python-amazon-product-api/0.2.5a1/python-amazon-product-api.pdf
Latest Amazon python api doc
https://media.readthedocs.org/pdf/python-amazon-product-api/latest/python-amazon-product-api.pdf
Thursday, September 21, 2017
Tokenize in python
Tokenize in python.
https://docs.python.org/3/library/tokenize.html
https://www.techopedia.com/definition/13698/tokenization
https://en.wikipedia.org/wiki/Lexical_analysis
https://docs.python.org/3/library/tokenize.html
https://www.techopedia.com/definition/13698/tokenization
Tokenization is the act of breaking up a sequence of strings into pieces such as words, keywords, phrases, symbols and other elements called tokens. Tokens can be individual words, phrases or even whole sentences. In the process of tokenization, some characters like punctuation marks are discarded. The tokens become the input for another process like parsing and text mining.
Tokenization is used in computer science, where it plays a large part in the process of lexical analysis.
Lexical analysis:
Serialize and deserialize in programming
Serialize and deserialize in programming:
https://en.wikipedia.org/wiki/Serialization

In python, we use pickle to do the serialization and deserialization.
https://docs.python.org/3/library/pickle.html
There is a .pkl file.
https://fileinfo.com/extension/pkl
In php, there is a serialize function.

How to run php code in windows.
http://editrocket.com/articles/php_windows.html
results of the program in php:
a:3:{i:0;s:5:"Lorem";i:1;s:5:"Ipsum";i:2;s:5:"Dolor";}
serialize in c++, geeksforgeeks.
http://www.geeksforgeeks.org/serialize-deserialize-binary-tree/
https://en.wikipedia.org/wiki/Serialization
In computer science , in the context of data storage, serialization is the process of translating data structures or object state into a format that can be stored (for example, in a file or memory buffer) or transmitted (for example, across a network connection link) and reconstructed later (possibly in a different computer environment).When the resulting series of bits is reread according to the serialization format, it can be used to create a semantically identical clone of the original object. For many complex objects, such as those that make extensive use of references, this process is not straightforward. Serialization of object-oriented objects does not include any of their associated methods with which they were previously linked.
This process of serializing an object is also called marshalling an object.The opposite operation, extracting a data structure from a series of bytes, is deserialization (which is also called unmarshalling).

https://docs.python.org/3/library/pickle.html
There is a .pkl file.
https://fileinfo.com/extension/pkl
In php, there is a serialize function.
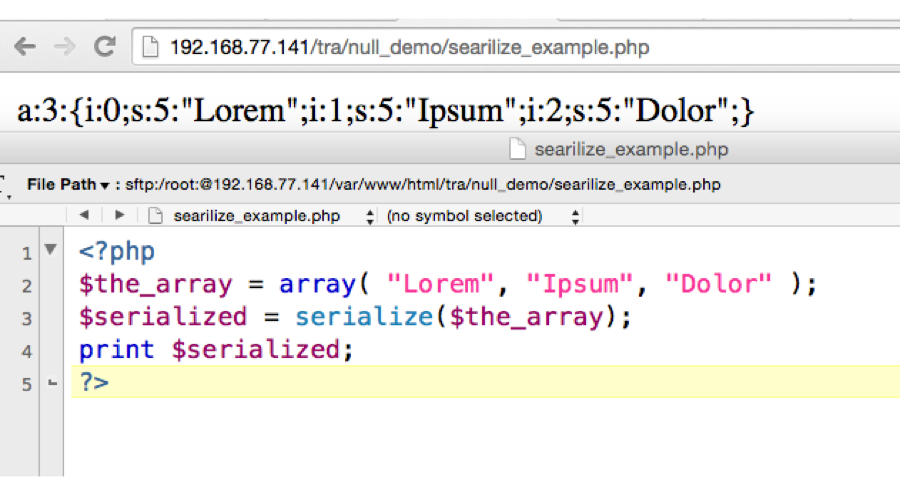
How to run php code in windows.
http://editrocket.com/articles/php_windows.html
results of the program in php:
a:3:{i:0;s:5:"Lorem";i:1;s:5:"Ipsum";i:2;s:5:"Dolor";}
serialize in c++, geeksforgeeks.
http://www.geeksforgeeks.org/serialize-deserialize-binary-tree/
Wednesday, September 20, 2017
How to improve programming skills
1. read, write as many lines of code as possible.
www.leetcode.com
http://poj.org/problem?id=2000
www.lintcode.com
http://www.jiuzhang.com/solutions/
http://codeforces.com/
www.github.com
https://projecteuler.net/
2. Do projects
3. study pattern design, objective oriented programming
https://www.youtube.com/watch?v=mym5m-GKG0Q
https://www.youtube.com/watch?v=j9arNRRoPe8
https://www.youtube.com/watch?v=0jjNjXcYmAU
https://www.youtube.com/watch?v=v9ejT8FO-7I
https://www.cp.eng.chula.ac.th/~wiwat/SDD/DP.pdf
4. learn as many as languages as you can , perl, python, java, js, scala, c, sh
www.leetcode.com
http://poj.org/problem?id=2000
www.lintcode.com
http://www.jiuzhang.com/solutions/
http://codeforces.com/
www.github.com
https://projecteuler.net/
2. Do projects
3. study pattern design, objective oriented programming
https://www.youtube.com/watch?v=mym5m-GKG0Q
https://www.youtube.com/watch?v=j9arNRRoPe8
https://www.youtube.com/watch?v=0jjNjXcYmAU
https://www.youtube.com/watch?v=v9ejT8FO-7I
https://www.cp.eng.chula.ac.th/~wiwat/SDD/DP.pdf
4. learn as many as languages as you can , perl, python, java, js, scala, c, sh
places to learn python/pandas
1. Stackoverflow
2. Books: Python for data analysis, Learning the Pandas Library
3. planetpython.org
4. data skeptic podcast,
dataskeptic.com
encode, decode, python
- Encoded. This is what's stored on disk. To Python, it's a bunch of 0's and 1's that you might treat like ASCII, but it could be anything -- binary data, a JPEG image, whatever. In Python 2.x, this is called a "string" variable. In Python 3.x, it's more accurately called a "bytes" variable.
- Decoded. This is a string of actual characters. They could be encoded to 8-bit ASCII strings, or it could be encoded to 32-bit Chinese characters. But until it's time to convert to an encoded variable, it's just a Unicode string of characters.
https://stackoverflow.com/questions/5228925/python-string-comparison-problems-with-special-unicode-characters
Tuesday, September 19, 2017
decode, encode, unicode, python
decode, encode, unicode, python
http://pythoncentral.io/python-unicode-encode-decode-strings-python-2x/
http://pythoncentral.io/python-unicode-encode-decode-strings-python-2x/
Friday, September 15, 2017
How to use douban v2 api
make a request sample:
https://api.douban.com/v2/movie/subject/1764796
you will get a json.
Other usage/example:
https://developers.douban.com/wiki/?title=movie_v2
https://api.douban.com/v2/movie/subject/1764796
you will get a json.
Other usage/example:
https://developers.douban.com/wiki/?title=movie_v2
Apai-io php example
Apai-io php example
https://github.com/Exeu/apai-io
https://github.com/Exeu/apai-io
<?php
namespace Acme\Demo;
use ApaiIO\Configuration\GenericConfiguration;
use ApaiIO\Operations\Search;
use ApaiIO\ApaiIO;
$conf = new GenericConfiguration();
$client = new \GuzzleHttp\Client();
$request = new \ApaiIO\Request\GuzzleRequest($client);
$conf
->setCountry('com')
->setAccessKey(AWS_API_KEY)
->setSecretKey(AWS_API_SECRET_KEY)
->setAssociateTag(AWS_ASSOCIATE_TAG)
->setRequest($request);
$apaiIO = new ApaiIO($conf);
$search = new Search();
$search->setCategory('DVD');
$search->setActor('Bruce Willis');
$search->setKeywords('Die Hard');
$formattedResponse = $apaiIO->runOperation($search);
var_dump($formattedResponse);
Tuesday, September 12, 2017
Friday, August 25, 2017
Tuesday, August 22, 2017
Friday, August 18, 2017
Wednesday, August 16, 2017
Thursday, August 10, 2017
Tuesday, August 8, 2017
Monday, August 7, 2017
omdb api not working any more
omdb api not working any more
https://stackoverflow.com/questions/44130398/unauthorized-http-401-r-omdbapi
https://stackoverflow.com/questions/44130398/unauthorized-http-401-r-omdbapi
imdbpie
imdbpie, how to use:
https://github.com/richardasaurus/imdb-pie
sample code:
https://github.com/richardasaurus/imdb-pie/blob/master/src/imdbpie/objects.py
Thursday, August 3, 2017
Wednesday, August 2, 2017
Scraping imdb and rotten tomatoes webpage without using API key
Scraping imdb and rotten tomatoes webpage without using API key :
http://rikunert.com/2017/05/11/star-trek-movies-ratings/
http://rikunert.com/2017/05/11/star-trek-movies-ratings/
python amazon simple product api
python amazon simple product api:
https://github.com/yoavaviram/python-amazon-simple-product-api/blob/master/amazon/api.py
https://github.com/yoavaviram/python-amazon-simple-product-api/blob/master/amazon/api.py
Monday, July 31, 2017
Amazon python, get number of reviews
import requests
nreviews_re = {'com': re.compile('\d[\d,]+(?= customer review)'),
'co.uk':re.compile('\d[\d,]+(?= customer review)'),
'de': re.compile('\d[\d\.]+(?= Kundenrezens\w\w)')}
no_reviews_re = {'com': re.compile('no customer reviews'),
'co.uk':re.compile('no customer reviews'),
'de': re.compile('Noch keine Kundenrezensionen')}
def get_number_of_reviews(asin, country='com'):
url = 'http://www.amazon.{country}/product-reviews/{asin}'.format(country=country, asin=asin)
html = requests.get(url).text
try:
return int(re.compile('\D').sub('',nreviews_re[country].search(html).group(0)))
except:
if no_reviews_re[country].search(html):
return 0
else:
return None # to distinguish from 0, and handle more cases if necessary
Saturday, July 29, 2017
How to build and use python package.
e.
distutils is a python standard package. It helps people to package, etc.
For example, we have a directory, and we have three files there, foo.py, bar.py, setup.py
And setup.py has the following content:
distutils is a python standard package. It helps people to package, etc.
For example, we have a directory, and we have three files there, foo.py, bar.py, setup.py
And setup.py has the following content:
from distutils.core import setup setup( name='fooBar', version='1.0', author='Will', author_email='wilber@sh.com', url='http://www.cnblogs.com/wilber2013/', py_modules=['foo', 'bar'], )
We run python setup.py sdist in that directory. And we will have a package named fooBar-1.0.zip.
And we can unzip the file, and "python setup.py install", and we can use "foo" , "bar" the two packages.
need to use "sudo chown -R $USER /usr/local/lib/python2.7" when run python setup.py install, otherwise permission denied.
List of python APIs
Here is a list of Python APIs:
http://www.pythonforbeginners.com/api/list-of-python-apis
I mainly focus on two of them:
Amazon Python API.
https://github.com/boto/boto
In fact it is boto package.
Here is a doc on Boto package, how to use it.
https://media.readthedocs.org/pdf/boto/latest/boto.pdf
Here is a video on boto:
https://www.youtube.com/watch?v=arhgSrqy1mM
The Linkedin API is
https://github.com/ozgur/python-linkedin
It is some package created from some user, and can complete some detailed application.
http://www.pythonforbeginners.com/api/list-of-python-apis
I mainly focus on two of them:
Amazon Python API.
https://github.com/boto/boto
In fact it is boto package.
Here is a doc on Boto package, how to use it.
https://media.readthedocs.org/pdf/boto/latest/boto.pdf
Here is a video on boto:
https://www.youtube.com/watch?v=arhgSrqy1mM
The Linkedin API is
https://github.com/ozgur/python-linkedin
It is some package created from some user, and can complete some detailed application.
Friday, July 28, 2017
List of Python APIs
List of Python APIs
http://www.pythonforbeginners.com/api/list-of-python-apis
one example, facebook, api:
https://github.com/sciyoshi/pyfacebook/tree/master/facebook
how to create a python package
how to create a python package on linux. details.
https://www.digitalocean.com/community/tutorials/how-to-package-and-distribute-python-applications
https://www.digitalocean.com/community/tutorials/how-to-package-and-distribute-python-applications
how to create a python package with wheels
how to create a python package with wheels
https://code.tutsplus.com/tutorials/how-to-write-your-own-python-packages--cms-26076
https://code.tutsplus.com/tutorials/how-to-write-your-own-python-packages--cms-26076
Thursday, July 27, 2017
python package minimal structure
python package minimal structure
http://python-packaging.readthedocs.io/en/latest/minimal.html
python package structure:
http://python-packaging.readthedocs.io/en/latest/minimal.html
python package structure:
app
├── __inti__.py
├── mod1
│ ├── file1.py
│ └── __init__.py
├── mod2
│ ├── file2.py
│ └── __init__.py
└── start.py
Wednesday, July 26, 2017
python console application example
python console application example:
https://stackoverflow.com/questions/9340391/python-interactive-shell-type-application
https://stackoverflow.com/questions/9340391/python-interactive-shell-type-application
import readline
import shlex
print('Enter a command to do something, e.g. `create name price`.')
print('To get help, enter `help`.')
while True:
cmd, *args = shlex.split(input('> '))
if cmd=='exit':
break
elif cmd=='help':
print('...')
elif cmd=='create':
name, cost = args
cost = int(cost)
# ...
print('Created "{}", cost ${}'.format(name, cost))
# ...
else:
print('Unknown command: {}'.format(cmd))
Python imdb, python rotten tomatoes
python imdb:
https://stackoverflow.com/questions/36513597/how-do-you-request-on-imdb-api-in-python
https://stackoverflow.com/questions/36513597/how-do-you-request-on-imdb-api-in-python
movies = {}
import json, requests
baseurl = "http://omdbapi.com/?t=" #only submitting the title parameter
with open("movies.txt", "r") as fin:
for line in fin:
movieTitle = line.rstrip("\n") # get rid of newline characters
response = requests.get(url + movieTitle)
if response.status_code == 200:
movies[movieTitle] = json.loads(response.text)
else:
raise ValueError("Bad request!")
print movies['scream']
import json, requests
url = "http://www.omdbapi.com/?t=scream"
response = requests.get(url)
python_dictionary_values = json.loads(response.text)
python rotten tomatoes:
https://www.blog.pythonlibrary.org/2013/11/06/python-101-how-to-grab-data-from-rottentomatoes/
https://pypi.python.org/pypi/rtsimple
Subscribe to:
Comments (Atom)
-
 Previously, I wanted to install "script" on Atom to run PHP. And there was some problem, like the firewall. So I tried atom-runner...
Previously, I wanted to install "script" on Atom to run PHP. And there was some problem, like the firewall. So I tried atom-runner... -
 I tried to commit script to bitbucket using sourcetree. I first cloned from bitbucket using SSH, and I got an error, "authentication ...
I tried to commit script to bitbucket using sourcetree. I first cloned from bitbucket using SSH, and I got an error, "authentication ... -
 Python classes: http://introtopython.org/classes.html Python object, instance, classes etc: https://www.tutorialspoint.com/python/pyth...
Python classes: http://introtopython.org/classes.html Python object, instance, classes etc: https://www.tutorialspoint.com/python/pyth...